At a recent meetup here in Amsterdam the uber friendly Stefan Armbruster showed how to do fun stuf with the APOC.
Although I did play around with the APOC earlier the demo was very inspirational and especially the “get data via JDBC” got stuck in my mind as being very useful in the very short term.
That same day (actually during the meetup) we got the message from a customer that our proposal for moving a website and data into the future was approved and we can go ahead and migrate the 7+ year old Django based website to new vital grounds.
Most of the website is actual just website stuff but back in the day Django was chosen as there was also an administration of memberships for both companies and individuals. That data is published partly on the site but also used for administrative purposes.
Traditionally I am moving data into the graph by either exporting it as CSV or by making a Python script as middlemen connecting to both the graph and the SQL datasource. This dataset is rather small but therefore even more interesting to try some new stuff on it.
Usually I have a VM in which Neo4J is running and development is done the VM; as this is still experimental I decided to do the stuff on my Mac instead.
The first hurdle was installing the APOC and JDBC plugins; it took a few moments before I realised that $NEO4J_HOME/plugins is actually inside the the /Applications/Neo4j folder and not somewhere else on the filesystem.
Go to your Applications folder; right click on the “Neo4J” application and “Show package contents”. Then click Contents, Resources, app and finally plugins. That folder is your friend.
Tough one eh? I thought so too.. Only much later I found that
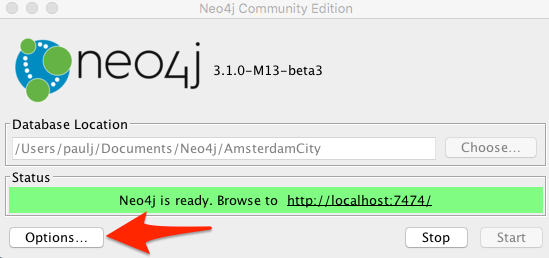
clicking that after clicking that friendly Options button and selecting “Plugins and extensions” navigates you to it directly:

Oh so convenient; especially for a command-line junkie with a Finder/GUI challenge 🙂
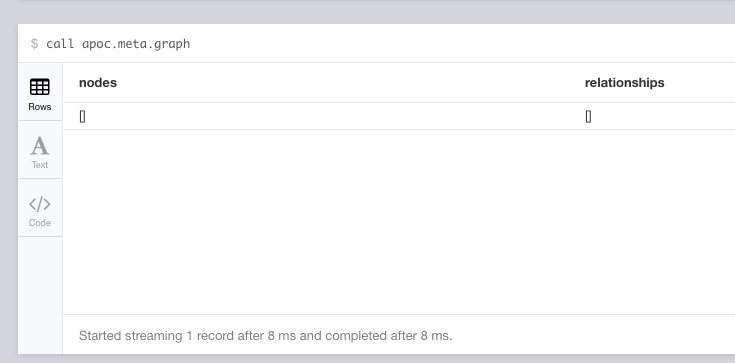
The easiest way I found for checking is Neo is picking up the APOC jar is by issueing a:
call apoc.meta.graph
in the console; it should respond with:
when the APOC did not register the response is less enthusiastic; like this:

Make sure to use the APOC releases page to find the matching version for your Neo4J instance. Trying to run a 3.0 APOC on your 3.1beta3 instance DOES NOT WORK.
The second struggle was getting the JBDC to work; although Stefan demo’ed it like it was no hassle at all it turned out that it actually is when you overlook simple things 🙂
First-most; the MySQL connector parameter used to pass the username to the database is called user and not username..
All the other parameters are documented here.
Getting the connection to work if the data is actually on a remote machine instead of a local MySQL server might involve firewalls and other nuisances. It might be good to check that your machine can actually connect to the database server by using other tools than the JDBC connector.
My first step is always to telnet to port 3306 of the server; if that does not connect the database-server is either not listening to the network or a firewall in between you and the server is blocking it. By doing the same telnet directly on the remote server (assuming you have shell access to it) you can determine if it listening on the IP or not.
Note that more recent releases of MariaDB are only listening to 127.0.0.1 by default. For a reason, exposing port 3306 on a public accessible IP might not be a good idea. To get to the data there is a simple trick which does not require any changes in the MySQL nee MariaDB configuration:
ssh -L 3306:localhost:3306 user@server
Tunnels the remote 127:0.0.1:3306 to a local “copy” of it; running this on your Mac makes it looks like it’s running locally; regardless of firewalls and configuration. As long as you have shell access to the remote server it works. Identification on the database level is still required but as long as you remember to type user instead of username all should be ok:
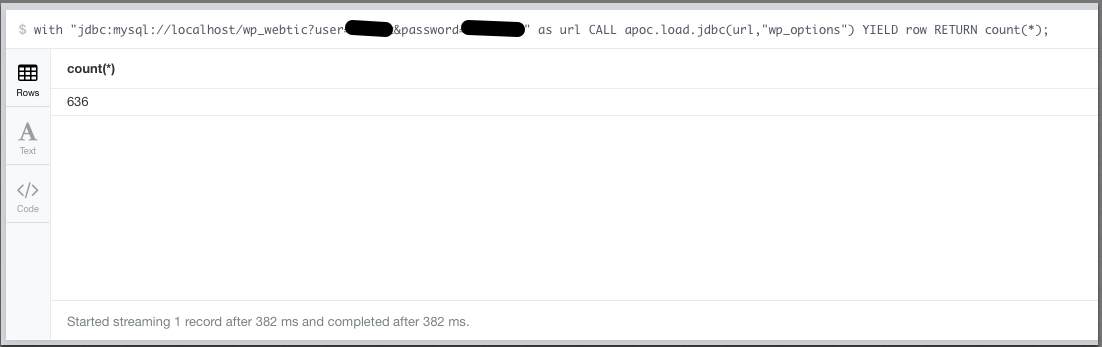
My muscle memory was “helping” by adding a / in the url like jdbc:mysql://localhost/wp_webtic/? ; don’t it won’t work. It really should be jdbc:mysql://localhost/wp_webtic? Adding that / results in an error: Access denied for user 'webtic'@'localhost' to database 'wp_webtic/‘ ; take that trailing slash as a hint to remove it 🙂
Another visual cue I found is that the response:
Access denied for user 'webtic'@'localhost' (using password: NO)
implies some sort of permission failure but at least the username got through; while when I was using ?username instead of ?user it said:
Access denied for user ''@'localhost' (using password: NO)
It took me a while but seeing that ” instead of ‘supplied username’ is actually a good hint that there are issues with passing the username 🙂
After all this tweaking we finally connected to a server successfully. And once it worked it’s easy to connect to other MySQL servers.. So I changed the parameters and connected to the live database of the customer:
with "jdbc:mysql://db.customer.com/Database?user=username&password=password" as url CALL apoc.load.jdbc(url,"Table") YIELD row RETURN row
That “Table” can either be a name of a table in the database or a query; I tried the tablename:
Unpackable value 2007-02-01 of type java.sql.Date
Not what I excepted but it seems to be some issue with a data; lets try something simpler:
with "jdbc:mysql://db.customer.com/Database?user=username&password=password" as url CALL apoc.load.jdbc(url,"Table") YIELD row RETURN row.name
And that works fine, confirming that probably some conversion does not work out due to the data format used in the database.
with "jdbc:mysql://db.customer.com/Database?user=username&password=password" as url CALL apoc.load.jdbc(url,"select * from Table limit 1 ") YIELD row RETURN row
Does give a good result, inspection confirms that the first record has an empty data field; as soon as a date is there it fails.
I changed the query to avoid dates and return them as a string:
apoc.load.jdbc(url,”select id,naam,contributiecat,contributie,concat(start_lidmaatschap) from Table limit 5″) YIELD row RETURN properties(row)
the result:
Byte array is not yet supported in Bolt
Bummer that did not work 🙁
Reading a bit more in the String functions of MySQL I encountered CAST(); lets try:
CALL apoc.load.jdbc(url,"select id,naam,contributiecat,contributie,cast(start_lidmaatschap as char) from Table limit 5") YIELD row RETURN properties(row)
And lo and behold there is data!
As always getting familiar with the tools was the biggest struggle; once that’s completed the JDBC route is a viable way of getting data from external sources.
I am quite sure that the migration can be done completely with Cypher; perhaps some unsupported string handling is needed which Cypher can’t do at the moment but that can be done on the SQL side. Or we can write a user defined function and add it to our toolbox.
But.. I doubt that at the current stage it is the easiest way. For situations where importing (new) data on a regular interval is needed it is worth to go this route as it can be done completely in Neo. However for this one-off migration with foreseen changes to both data and model I probably will whip up some Python script to do all the work. Being very familiair with those tools that seems the most efficient route for this project.
That said, I am certain that APOC will keep a permanent place in my toolbox, accompanied by some JDBC where needed.
Remember to have a look in your toolbox and add some shiny new tools if you like them 🙂
Not sure if APOC is for you? Browse https://neo4j-contrib.github.io/neo4j-apoc-procedures/ to whet your appetite!