In MySQL days getting an unique key was a matter of creating a field and tag it with the auto_increment feature. The database engine would do the rest and nice sequential unique numbers were added for each record. The predictability of these keys made them less useful in situations where such a key is visible, say for instance in a url.
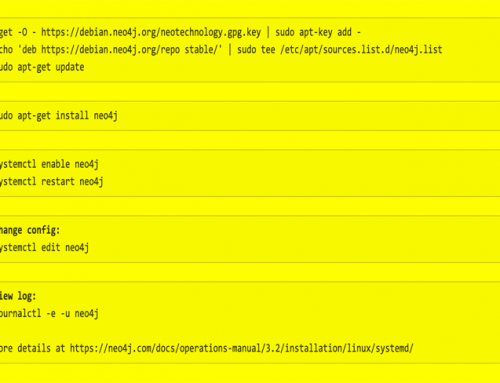
One easy way to get rid of the sequence is using a UUID instead. When using a Neo4J Graph database nothing is easier than adding a uuid property and set its value. If you need a unique key to the node it is preferred way. You might be tempted by using the id() of a node but don’t do that. There is no guarantee that particular node will keep that number for ever.
One interesting approach of adding UUID’s to Graphs is by extending Neo itself but I’d prefer to do it in the application itself to keep a bit more control as I only want uuids on some nodes not on all of them.
In an existing project which uses Neomodel I typically define it like :
from neomodel import (StructuredNode, StringProperty)
from uuid import uuid4
class ContentItem(StructuredNode):
uuid = StringProperty(default=uuid4, unique_index=True)
title = StringProperty(required=True)
...
Whenever a node is saved it will automatically call the uuid4 function which return a nice new uuid and uses that as a key. If there is a key nothing is done. Good stuff. When you add a uuid like that later don’t forget to re-save all your nodes otherwise the uuid field will have a random new value everytime you retrieve the node. That might do funny things to your app 😉
For a new project which is starting I’d like to get rid of the Neomodel dependancy for reasons outlined in this previous post. While pondering about it I realised that during imports I might be needing 30.000 or more uuid’s at a single go. This made me wonder how fast the generating of them actually is.
from uuid import uuid4
for i in range(0,30000):
u = uuid4()
and run
atom:uuidtest paulj$ time python uid.py real 0m0.622s user 0m0.385s sys 0m0.223s
Not too bad, so how about a million of them?
real 0m17.488s user 0m11.711s sys 0m5.749s
It’s getting hard work, so how about 10.000.000?
real 3m9.005s user 2m5.535s sys 1m2.976s
The changes of needing these amounts are less than zero but it is Friday and it has been ages since I did some premature optimalisation so just out of interest I decided to check how Go is doing in the uuid domain.
The first hit on “golang uuid” is this Stack Overflow discussion which mentions two packages: github.com/nu7hatch/gouuid and github.com/twinj/uuid
Both are very similar in usage:
package main
import "github.com/nu7hatch/gouuid"
//import "fmt"
func main() {
for i := 0; i < 10000000; i++ {
_, _ = uuid.NewV4()
}
}
and:
package main
import "github.com/twinj/uuid"
//import "fmt"
func main() {
//u := uuid.NewV4()
//fmt.Println(u)
for i := 0; i < 10000000; i++ {
_ = uuid.NewV4()
// u:= uuid.NewV4()
// fmt.Println(u)
}
}
I commented out the statements I used to check the output, we are not benchmarking stdio. The _ is the funny way in Go to indicate that you actually ignore the return value, it is needed otherwise the program won't run. Both are very similar in performance:
atom:uuidtest paulj$ time go run nu7hatch.go real 0m12.164s user 0m2.348s sys 0m10.512s
and
atom:uuidtest paulj$ time go run twinj.go real 0m12.136s user 0m2.281s sys 0m10.405s
Where Python needs minutes Go goes through it in seconds, and this appears to be only the start.. Sort of surprised there was no "default" package in Go for generating uuid's I googled some more and found a few others.. One of them being code.google.com/p/go-uuid/uuid which is even a lot faster:
package main
import "code.google.com/p/go-uuid/uuid"
//import "fmt"
func main() {
for i := 0; i < 10000000; i++ {
//u := uuid.NewUUID()
//fmt.Println(u)
_ = uuid.NewUUID()
}
}
and its results:
atom:uuidtest paulj$ time go run go_uuid.go real 0m2.248s user 0m2.200s sys 0m0.153s
The generated uuid's are less random than the other two packages,
8bb7b767-1101-11e5-aeeb-94de80b5e095 8bb7c4c0-1101-11e5-aeeb-94de80b5e095 8bb7c4eb-1101-11e5-aeeb-94de80b5e095
versus
{413F7C38-BC59-4FED-95BD-65158DAF9FE7}
{0265D466-01FD-4654-A0C4-953CCE4726B5}
{A0B17BE3-7BE3-4077-8677-EAC4D18CA92B}
so it might be good to look at the actual implementation before settling on a specific package. And as mentioned there are many others. Googling on "gaoling uuid" opens a world of different implementations. Obviously others than myself were wondering about the "best one" as early as in 2013.
Perhaps one "best" implementation will end up in the standard library one day. For now doing 30.000 plus in Python seems very ok, and if needed there is an escape..
Remember: there are lies, damned lies and statistics. But benchmarks top all of these 😉
These were done on my personal workstation, a Core i7 @3.7Ghz running Yosemite.