While creating a proof-of-concept import for an existing website I needed to associate paths with downloads which are stored in two separate workbooks in an Excel worksheet.
The path is a typical subject tree A -> B -> C -> D ; every step down the tree is more detailed and on any of these levels one or more content-items can be associated.
The current website lives in a SQL database and this subject-tree has always been a painful thing. Importing the tree and translating it to a SQL model is cumbersome and takes quite a bit of pre-processing before it can actually be stored in the SQL database.
Having more than moderate success with Graphs and especially Neo4J I started wondering how much work it would be to transform that site to the Graph. Importing the paths was the main pain in the old system so I started working on that specific issue. The list of subjects is incremental, typical one would have a list like this:
A
A - B
A - B - C
A - B - C - D
To convert and import it into Neo4J I decided to use Python, the old import tool is also made in Python and it has excellent support to read the native .xlsx format in which the meta-information is stored.
The hardest part of building stuff in Neo/Cypher is to loose all the SQL thinking you are so used to. I knew the model was very easy to express but I wasn’t too sure on how the script would build it. I realised writing a script that creates and links each node seperately was not the ideal approach. It takes a lot of processing and checking for duplicate names in the actual nodes would complicate matters as the terms used in the paths where not unique.
While pondering I was screening the manual and I stumbled upon the MERGE keyword. It seemed ideal, it only creates stuff if it isn’t there and you can feed it a complete path. So both my duplication and level dilemma where solved, or so I thought!
Gladly ignoring the explanatory text of the manual page I glanced at the examples and was already crafting queries in my mind. Quickly I started experimenting and all looked fine. MERGE the saviour!
After some work a first version of the import script was done and it ran flawless. Or so it seemed. On closer inspection there was something funny, it seemed that there where several duplicates of the paths imported. Wasn’t it supposed to merge those? As in “To combine or unite into a single entity”?
A day later I met Mark Needham on GraphConnect and after mentioning the issue he promised to look into it if I could illustrate it in a simple example. Instead of firing up the editor I went to Cypher console and typed:
merge (a:Navigation {name:'A'})-[:IN]->(b:Navigation {name:'B'})
and Neo reported:
Created 2 nodes, set 2 properties, created 1 relationship, statement executed in 38 ms.
Righto, the database was empty so everything needs to be created and so it does, all perfect. So I continued with adding an extra level:
merge (a:Navigation {name:'A'})-[:IN]->(b:Navigation {name:'B'})-[:IN]->(c:Navigation {name:'C'})
and Neo said:
Created 3 nodes, set 3 properties, created 2 relationships, statement executed in 82 ms.
Ho stop right there, what is going on? Creating another three nodes? A quick view confirmed this:
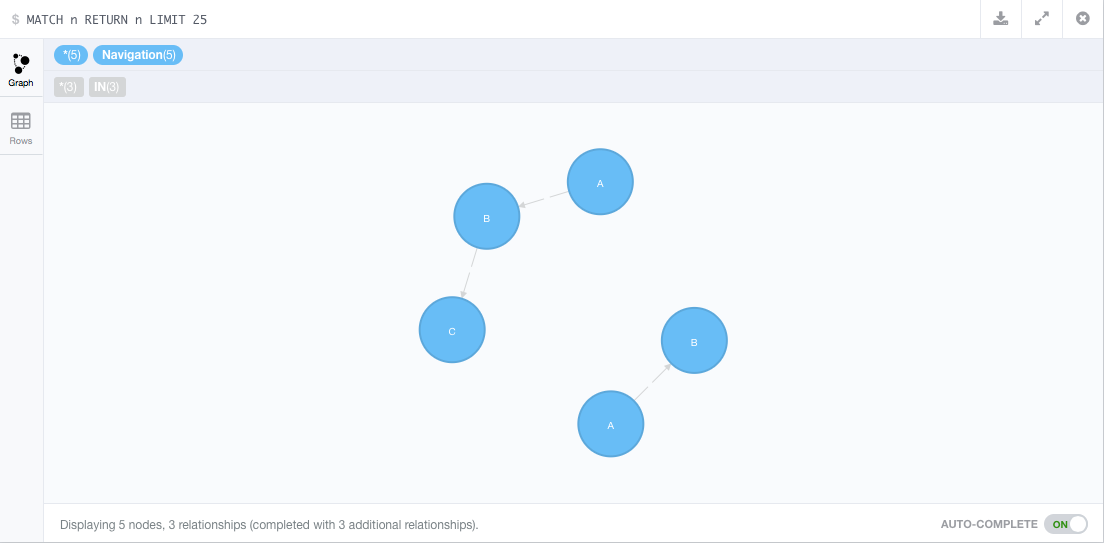
Two separate paths, not what I expected. Perhaps it’s because I am working with paths and not properties. In the manual page there is an example involving Charlie Sheen, so I fired off these two commands:
MERGE (charlie { name:'Charlie Sheen'})
MERGE (charlie { name:'Charlie Sheen', age:10 })
And voila, two separate instances of Charlie.

Confused I mailed Mark and patiently he wrote back that what I saw was conform expectation. It took another mail from him to see what was actually stated in the first line of the manual: “MERGE either matches existing nodes and binds them, or it creates new data and binds that. It’s like a combination of MATCH and CREATE".
So yes, it all is correct, there is no node with name and age the first time around, there is one with only the same name but technically that is not the same indeed, so it creates one. #snafu, I was expecting more than this somehow.. Sorry for that..
For this particular import case it is not a problem at all, I just need to scan all paths and only create (nee: merge) the longest unique ones, problem solved. The ability to create a complete path is a great timesaver so all is good in the end.
Neo4J is a great product and working with it is a joy, perhaps some day we will even get a MAGICMERGE command 🙂
It’s all about the learning curve I guess, once every while you roll back a little only to come back with more skills..